Howard Marks Went Looking for an AI Bubble. He Found Something Else.
The memo Warren Buffett will read before anything else this weekend.

Three months ago, Howard Marks published a memo called “Is It a Bubble?” — a careful, measured look at whether the AI trade had got ahead of itself. It was deliberately inconclusive. He weighed both sides, acknowledged the uncertainty, and left the question open.
Yesterday, he came back with an addendum. It’s called “AI Hurtles Ahead.” And the tone has shifted.
If you invest and you don’t read Howard Marks, I recommend you start. He’s been writing memos to Oaktree Capital’s clients for over three decades, and they’re some of the clearest thinking you’ll find anywhere in finance.
Marks isn’t a stock picker — he built Oaktree into the world’s largest distressed debt investor — but his ability to frame how to think about markets, risk, and cycles is unmatched. Warren Buffett once said: “When I see memos from Howard Marks in my mail, they’re the first thing I open and read. I always learn something.” Not a bad reference to have on your CV.
In this memo, Marks did something unusual. He used Claude — Anthropic’s AI model — to build himself a personalised tutorial on artificial intelligence. He spoke to technologists in their thirties and forties. He went deep into the weeds. And the more he found, the more convinced he became.
Not recklessly so — this is still Howard Marks, the man who wrote “The Most Important Thing” and built a career on caution. But he’s no longer sitting on the fence. He’s saying: this is real, it’s moving faster than anything we’ve seen before, and its potential is more likely being underestimated than exaggerated.
I've been on a similar journey. Over the past three months I went down the AI rabbit hole — not just reading about it, but building with it.
I've used Claude Code to create research systems tailored to my own portfolio, not generic output or research pushing someone else's agenda. I built a portfolio tracking app for my phone. I can't write a line of code. That told me everything I needed to know about where this technology already is.
That process — going from curious to convicted through direct experience — is exactly what Marks describes in this memo. And it’s why I think it’s worth breaking down.
The argument that ended a philosophical debate
The section that stopped me was Marks recounting a debate between AI sceptics and Claude itself.
The sceptics’ argument is familiar: everything AI produces is ultimately a rearrangement of patterns absorbed from human-created text. Impressive pattern matching, perhaps the most sophisticated ever engineered, but not real thought. Not reasoning. “A talented cover band, not a composer.”
Claude’s response — which Marks reproduces in the memo — is devastating in its simplicity.
It essentially argued: “Howard, everything you know about investing came from other people too. Graham taught you about margin of safety. Buffett taught you about quality. Munger taught you about mental models from multiple disciplines. You absorbed all of it from external sources, synthesised it, and produced something new. How is that structurally different from what I do?”
It’s one of those arguments that’s so obvious once you hear it that you can’t believe you hadn’t framed it that way yourself. Every investor, every thinker, every creative person builds on inputs from others. The question isn’t where the raw material came from. The question is whether the synthesis produces something genuinely useful.
And then came the line that ended the philosophical debate: the economic question isn’t whether AI truly understands — it’s whether it does the work. And increasingly, it does.
The distinction that changes everything
Marks lays out three levels of AI capability, drawn from his tutorial with Claude:
Level 1 is chat. You ask questions, you get answers. It saves you research and thinking time, but it doesn’t do anything with those answers. Useful, but limited.
Level 2 is tool-using AI. You instruct it to find information, analyse it, and perform tasks. More valuable, but still bounded by what you tell it to do.
Level 3 is autonomous agents. You give it a goal and parameters. It does the work, checks it, and delivers a finished product. Not assistance — replacement, at the task level.
According to Marks, AI was at Level 1 in 2023 and Level 2 in 2024. It’s now at Level 3. And the shift from Level 2 to Level 3 is, in his words, the difference between a productivity tool and a labour substitute — between a market worth fifty billion dollars and one worth multiple trillions.
He cites the pace of change to make this tangible:
In 2022, AI couldn’t do basic arithmetic reliably
By 2023, it could pass the bar exam
By 2024, it could write working software and explain graduate-level science
By late 2025, some of the best engineers in the world had handed over most of their coding work to AI
On February 5th 2026, new models arrived that made everything before them feel like a different era
Nothing in history has moved this fast. Marks compares it to the computer, which took nearly forty years from ENIAC’s creation in 1945 to widespread commercial use in the early 1980s. AI has gone from background technology to something being used at enormous scale in roughly two years.
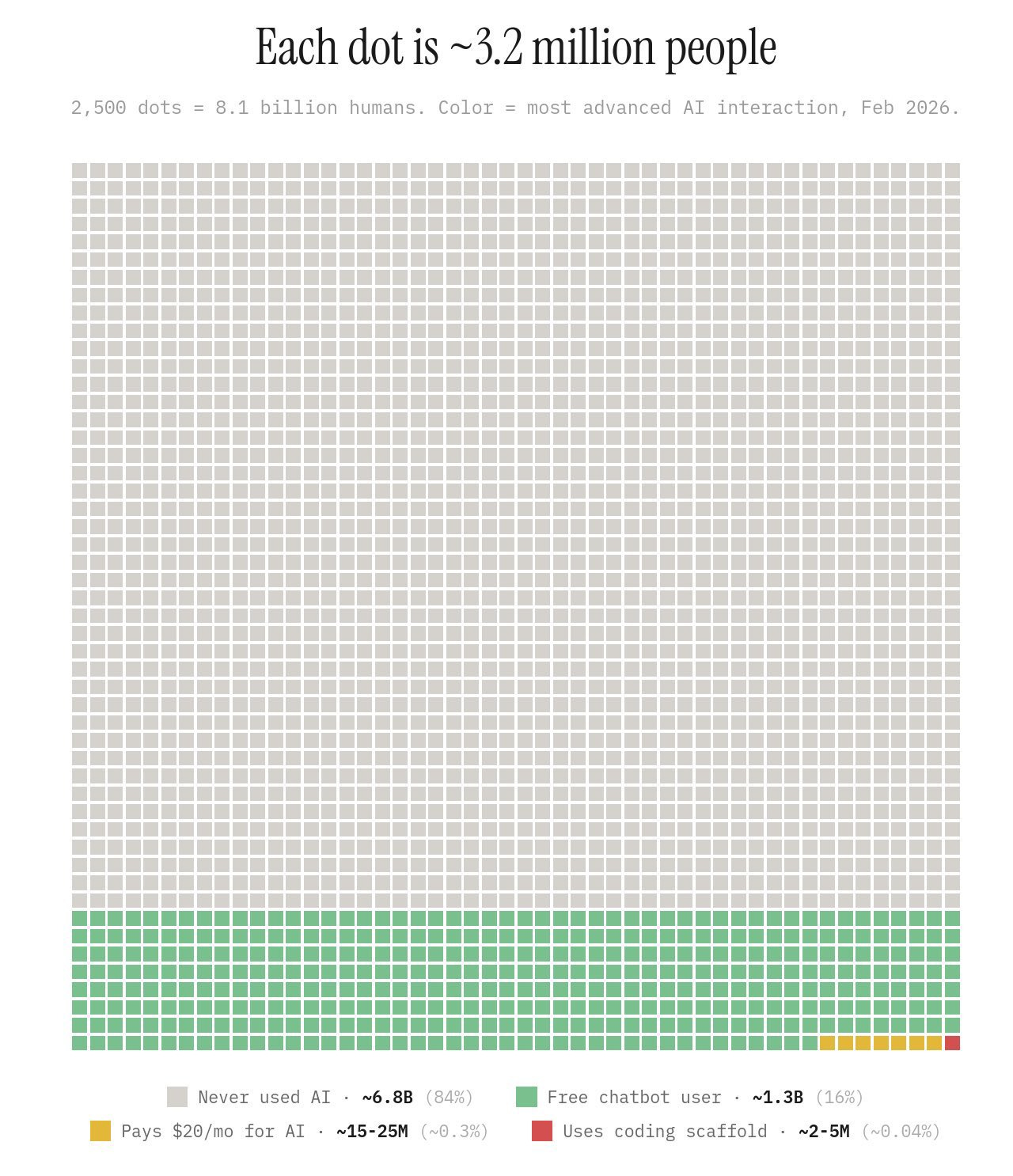
And yet — we’re still incredibly early. I recently saw a graphic that puts this in perspective: as of February 2026, approximately 84% of the world’s population has never used AI at all. Around 1.3 billion people have used a free chatbot. Only 15 to 25 million pay for an AI tool. And just 2 to 5 million use AI coding tools. Those numbers put the “400 million users” figure Marks cites in context, but more importantly, they tell you where we are on the adoption curve. We’re at the very beginning.
So is it a bubble?
This is where Marks is at his best. He doesn’t answer the question with a yes or no. He breaks it into separate questions, each with a different answer.
Is the technology real? Yes, with conviction. Is it already being applied at scale? Yes. Is some of the infrastructure spending going to be wasted? Almost certainly — that’s what happens in every major technological buildout. History is littered with capital destroyed in the rush to build infrastructure for genuine innovations. Railways were real; most railway investors still lost money. There’s no reason to assume this time will be different.
But the crucial distinction most commentators miss is this: the technology being real and transformative does not automatically mean the investments are cheap. Both things can be true simultaneously.
Marks draws a clear line between the hyperscalers — Microsoft, Amazon, Google — and the speculative start-ups being valued at billions before they’ve even described their products. The hyperscalers are enormously profitable companies for whom AI is one important growth driver among several. It’s unlikely, in his view, that buying these businesses at today’s prices will prove catastrophic over a decade. The start-ups with no revenue and astronomical valuations? Those are lottery tickets. Most people who buy lottery tickets end up with nothing. A few end up very rich.
Marks also notes that AI spending is increasingly shifting toward inference — running models to serve actual user demand — rather than speculative training. That’s customers showing up and paying, which is a fundamentally different risk profile.
One of the biggest fears around AI investment is that we’re building vast amounts of infrastructure that won’t be needed — either because demand falls off, or because the technology becomes so efficient that all this compute becomes redundant. But history suggests the opposite. This is Jevons paradox. When steam engines became more efficient in the 19th century, coal consumption didn’t fall — it rose dramatically, because efficiency unlocked new applications that weren’t previously economical. More efficient AI models won’t reduce demand for compute. They’ll make AI viable for use cases we haven’t imagined yet, and total demand will expand. The infrastructure buildout may look excessive at any given moment, but directionally, the demand curve is going one way.
The part that kept me thinking
The final section of the memo deals with AI’s implications for jobs and society. Marks is openly worried. He can see the displacement coming — in advertising, software, driving — and admits he can’t foresee where enough replacement jobs will materialise.
I share his concern, but I’d add a layer of nuance from my own experience helping run our family-owned logistics and project shipping business. Take autonomous driving, which Marks flags as a major source of future job losses. He’s not wrong about the direction. But the reality on the ground is more complicated than “trucks drive themselves and drivers disappear.”
The hardest parts of a truck journey aren’t the motorway. They’re the first mile and the last mile — navigating a port, reversing into a loading bay, dealing with the unpredictable chaos of an industrial site. Full autonomy for those tasks is still a way off. What’s much more plausible — and closer to reality than most people think — is a hybrid model. Drivers based at ports and factories handle the complex first and last miles. The truck drives autonomously on the motorway. The middle section is monitored remotely by an operator at a base, like a drone pilot overseeing multiple vehicles at once.
That’s not job elimination. It’s job transformation. The drivers go home to their families every night instead of sleeping in a cab on the M1. The remote monitoring role is a new job category that didn’t exist before. The work changes shape, but it doesn’t simply vanish.
That said, Marks is right that the speed of change will outpace society’s ability to adjust.
The tech optimists point out that every previous revolution — mechanisation of agriculture, the industrial revolution, the internet — was predicted to cause mass unemployment, and new jobs always materialised. They’re not wrong historically. But AI is different in kind, not just magnitude. Previous technologies automated physical tasks. AI automates thinking. And it’s moving at a pace that makes retraining and adaptation extraordinarily difficult.
Marks doesn’t have a neat answer for this. Neither do I. His closing thought — that he’d rather be an optimist and wrong than a pessimist and right — is honest in a way that most commentary on this subject isn’t.
The thread keeps going
Marks ends where he ended in December: don’t go all-in without acknowledging the risk of ruin, but don’t stay all-out and risk missing one of the great technological leaps forward.
What strikes me is the trajectory of his own thinking. In December, the question was open. Three months later, the evidence has moved him. Not toward recklessness — toward conviction. Every thread he pulls reveals more substance, not less. Every time he looks deeper into AI, he finds more reasons to believe this is genuinely transformative and fewer reasons to dismiss it.
I suspect he’ll write another memo on AI before the year is out. And I suspect the thread will still be going.
Read the full memo on Oaktree’s website. It’s worth your time.
Disclaimer: This publication is for informational and educational purposes only. It is not financial advice. I hold positions in securities discussed and may buy or sell at any time without notice. Always do your own research and consult a qualified professional before making investment decisions.
Thanks for summarizing and more importantly providing your own color, Robert. But a few things are taken a little too easily for granted.
What you deem a breakthrough thought from Claude is actually exactly what is wrong with LLMs. It seems plausible and clever, but it is actually… wrong. The difference between training an LLM on the corpus of human knowledge and how humans learn is that LLM training is a one-off pattern and sense-making exercise, based on whatever it is fed. That is not how you, I, or Marks synthesize data. We do it in real time, with learning and adaptation. Philosophically, an LLM is stateless. It will not learn or adapt after its training. You can spend an entire conversation teaching an LLM that your specific industry uses a term in a non-standard way, and it will adapt within that session. Open a new window the next day and it has forgotten everything. It has not learned. It has no continuity. That is what statelessness means, and that is what separates it from how Marks absorbed lessons from Graham and Buffett over decades of practice.
Another problem with LLMs is temperature sampling: the ‘creativity’ it is allowed to deploy and provide variation in its answers. In reality this means that the same prompt in a different conversation will provide different outcomes. You can test this yourself by opening ten chat windows and feeding ChatGPT the same riddle ten times. You will see differences. And even if it gets it right 8 out of 10, that means 20% was wrong.
This brings me to point two. LLMs are technically not suited for the kind of agentic Level 3 application that Marks describes. The transformer architecture is fundamentally a next-token predictor. It does not plan, verify, or course-correct. When you chain multiple steps together in an agentic workflow, each step carries a probability of error, and those errors compound multiplicatively. A 95% accuracy rate across twenty chained steps gives you a 36% chance of getting the whole sequence right. That is not a labor substitute. That is a liability. Autonomous agents need to know when they are wrong, and LLMs do not know what they know. They generate plausible outputs with equal confidence whether the output is correct or fabricated. In a chat window that produces a useful paragraph, hallucination is an inconvenience. In an autonomous agent making consequential decisions without human review, hallucination is a structural failure mode. Marks conflates the impressive fluency of the interface with the reliability of the underlying architecture. Level 3 requires persistent state, verifiable reasoning, and real-time error correction. Current LLMs offer none of these.
The third point is the infrastructure buildout, which is treated rather simplistically. You refer to railroads. Those were indeed economically viable for years after installation. The problem is that data centers, and more specifically the GPUs inside them, have a technical lifespan of maybe two or three years. Nvidia is releasing new generations within an eighteen to twenty-four month cycle, and performance improves between three and five times between generations. Meanwhile, hyperscalers are depreciating these assets over five or six year spans. The problem this creates is serious. If I buy this generation and my competitor buys the next, my data center is suddenly far less viable, filled with assets I am still depreciating for another three years. Railroads do not become obsolete every two years. GPUs do. So we’re looking at investment patterns that resemble infrastructure projects like roads and bridges, with the unit economics of an iPhone.
I think Marks is seduced by the charms of Claude. The sceptic vs proponent argument is basically “its statistics” vs “does it matter if the output is good”. Intelligence evolves from an evolutionary need, reasoning and intelligence evolves in the context of stakes, incentives, caring, and suffering (aka survival). The statistics has none of those things.